안냥하세요
오늘 주제는 인덱스
관련 내용을 한 번에 쓰려다가 내용이 드릅게 길어져서 둘로 나눕니다.
이 글의 내용은
1. 혼자 공부하는 SQL (책)
2. 코딩애플 (유튜브)
3. 쉬운코드 (유튜브)
의 내용을 많이 참고했습니다.
관련 지식이 없다면 글을 보기 전에 코딩애플 아저씨 영상을 보면 좋다.
쉬운코드 아저씨 영상은 좀 더 깊이있지만 영상이 길어서 따로 첨부하지 않음.
==1편(활용). 본 게시글==
1. 인덱스를 사용하는 이유
2. 인덱스의 기본적인 원리 (그림 설명)
3. DBMS에서 실습해보기 - 준비
4. DBMS에서 실습해보기 - 실전
==2편(원리)==
1. Unique Index, Non-Unique Index 차이
2. 인덱스를 사용하지 못하는 경우 - 다중 컬럼 인덱스(Multiple-Column Index)
3. 커버링 인덱스(Covering Index)
4. 인덱스를 사용하지 못하는 경우 - 선행 와일드카드
[DB]인덱스에 대한 이해- 2부(다중 컬럼 인덱스, 커버링 인덱스, 선행 와일드카드)
[DB]인덱스에 대한 이해- 1부 안냥하세요 오늘 주제는 인덱스 관련 내용을 한 번에 쓰려다가 내용이 드릅게 길어져서 둘로 나눕니다. 이 글의 내용은 1. 혼자 공부하는 SQL (책) 2. 코딩애플 (유튜브)
moolzumdao.tistory.com
1. 인덱스를 사용하는 이유와 근본적 원리
어떤 자료 뭉탱이(배열 등)에서 원하는 값을 찾고 싶을 때가 있다.
그럴 때 우리는
'선형 탐색' 혹은
'이진 탐색' 을 할 수 있는데,
선형 탐색은 정직하게 배열의 처음부터 끝까지 탐색하는 것이고,
이진 탐색은 '정렬된 자료에 한해서' 아래와 같이 수사망을 반씩 좁혀가며 탐색하는 것이다.

이진 탐색은 데이터를 반으로 갈라 죽이면서 수사망을 좁히기 때문에
데이터 N이 100개일 때
선형 탐색 - 탐색 작업을 정직하게 100번 해야 함 - O(N)
이진 탐색 - 반씩 잘라서 날먹해서 7번만에 끝냄 - O(logN)
그치만 우리의 콤퓨타 씨는 더럽게 빠르기 때문에
데이터가 엄청나게 많지 않은 이상
선형 탐색과 이진 탐색의 속도차이는 사람이 눈치채기 힘들 것이다.
정직하게 처음부터 끝까지 찾는 선형 탐색을 하는 속도조차 너무 빠른 것이다.
하지만 데이터베이스처럼 수많은 사용자 요청에 의해서 많은 데이터가 쌓이는 경우는 어떨까?
데이터가 많아지면 컴퓨터도 힘들어해서 '수사망 좁히기' 탐색을 적극 활용해야 하는데,
이러한 이진 탐색의 원리를 기반으로 해서 데이터베이스의 조회 성능을 개선하는 것이 바로
'인덱스'이다.
2. DB에서의 인덱스
관계형 데이터베이스는 테이블 형식으로 데이터를 관리한다.
인덱스라 함은 해당 테이블에서
'일부 컬럼(multi column index일 수도 있지만 여기서는 하나라고 가정)'을
떼어와서 정렬해놓고, 정렬된 데이터를 바탕으로 빠른 검색을 돕는 기능이다.
아래 사진으로 인덱스를 이해해 보자.
1. Name
2. Id
3. Department
3개의 필드를 가지는 테이블이 있고, 'Name'을 대상으로 인덱스를 생성한다고 가정하자.
인덱스의 대상이 되는 자료형이 숫자가 아니어도 상관없다.
인덱스에 알파벳 오름차순으로 Name(Search Key)데이터가 정렬되어있기 때문에 Alice를 찾는 시간은
O(logN)이다.
Select * From Employee Where name = 'Alice' 를 실행하면,
1. O(logN)의 빠른 속도로 인덱스에서 Alice를 찾는다.
2. 인덱스 데이터가 들고 있는 주소값(사진에서는 Pointer to Disk Location)을 사용해서
원본 테이블의 데이터(row)를 확인한다.
3. 원본 row의 데이터를 출력한다.
만약 인덱스를 등록하지 않았다면 어떻게 될까?
DEPARTMENT에 대한 인덱스를 만들지 않았다고 가정하자.
"Select * From Employee Where Department = 'Marketing' "를 실행하면,
1. 테이블의 처음부터 끝까지 선형 탐색하며 Department = 'Marketing'인 데이터를 찾는다.
이를 데이터베이스에서는 Full Scan이라고도 부르며,
데이터의 개수만큼 정직하게 속도가 느려지는 O(N)의 시간복잡도를 갖는다.
(심지어 Unique Index가 아니라면 데이터를 찾았더라도 테이블의 끝까지 스캔한다.
즉 Best Case가 의미가 없어진다.)
2. 찾은 데이터(들)을 출력한다.
그럼 이제 실제로 DBMS에서 인덱스를 만들어보고 테스트해보자.
3. DBMS에서 실습해보기 - 준비
DB: MariaDB
GUI: DBeaver
테스트용 테이블인 'nTable'의 구조는 다음과 같다.
1. id - Auto Increment PK
2. email
3. idxname
4. name

DDL은 다음과 같다.
create table nTable(
id INT AUTO_INCREMENT PRIMARY key,
email VARCHAR(255) not null,
idxname VARCHAR(255) not null,
name VARCHAR(255) not null
);
테스트용 데이터는 500만건으로, 데이터 삽입은 GPT님이 만들어주신 Stored Procedure를 사용했다.
DELIMITER //
CREATE PROCEDURE InsertMultipleRows(IN num_rows INT) // 프로시저 생성
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= num_rows DO
INSERT INTO nTable (email, idxname, name) VALUES (CONCAT('Name ', i), CONCAT('Name ', i), CONCAT('Name ', i));
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
CALL InsertMultipleRows(1000000); // 프로시저 Call그러면 아래와 같은 데이터가 나온다.
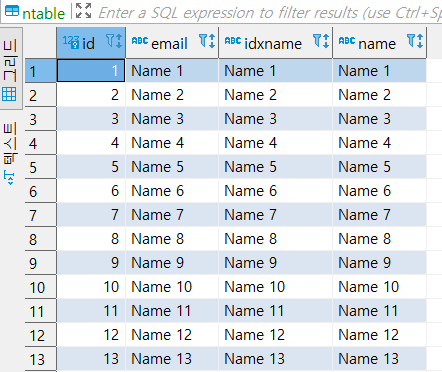
모든 데이터가 정렬되어 있는 '것처럼' 보인다.
숫자를 1씩 늘려가며 데이터를 삽입해서 그렇게 보이는 것이다.
내가 숫자를 1씩 늘려가면서 데이터를 삽입했는지 아닌지는 DBMS(의 Query Optimizer)는 모르기 때문에,
저 중에 데이터 하나를 찾으려면 DBMS는 Full Scan을 실행한다.
(사실 실제로 정렬되어있는 것은 PK 뿐이며, 이는 Clustered Index에서 설명)
준비가 끝났으니 실제로 여러가지 테스트를 해 보자.
4. DBMS에서 실습해보기 - 실전
데이터 하나를 검색하기 전에
전체 데이터 수를 count()로 알아보자.
select count(*) from ntable n ; // 50010000501만개의 데이터가 존재한다.
name 하나를 조회해보자.
일단 실행계획(Execution Plan)을 확인해보자.
explain
SELECT * FROM ntable n where n.name = 'Name 313131';
type = ALL.
'너 이거 실행하면 Full Scan됨'
이라는 뜻이다.
실제로 돌려보자.
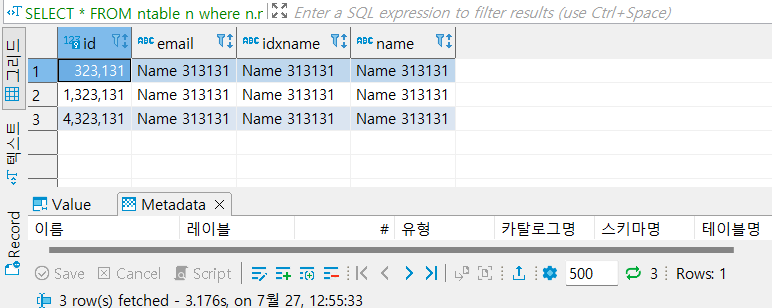
3초가 걸렸고,
3개의 데이터를 찾았다.
실제 서비스라면 네트워크 I/O와 같은 기타 작업들을 거치면 3.5초 이상 걸렸을 것 같다.
충분히 사용자가 불편해할 수 있는 수치이다.
id로도 검색해보자.
실행계획부터 확인해보자.
explain
SELECT * FROM ntable n where n.id = 313131;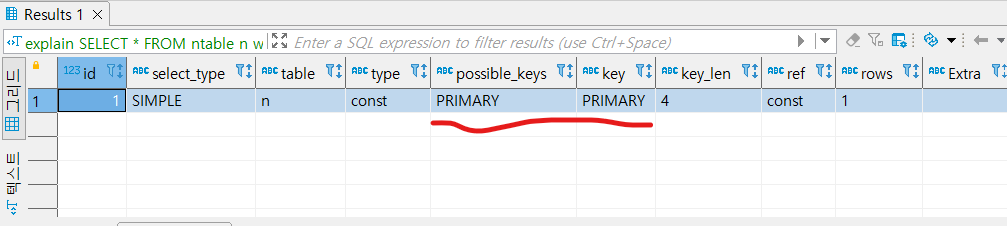
name을 찾는 실행계획에서는
possible_keys (후보 인덱스), key (후보 인덱스 중 선택된 인덱스)
모두 null이었다.
지금은 사용할 인덱스를 찾은 것이다.
즉, id로 검색을 할 때의 실행계획에서는 인덱스를 사용하겠다고
Query Optimizer가 판단한 것이다.
DBMS는 처음 테이블을 만들 때, PK 컬럼에 대해서 자동으로 인덱스를 등록한다.
자세한 내용은 2부에서 이야기하겠지만,
PK, Unique Key, FK는 자동으로 인덱스가 등록된다.
(자세한 내용은 DBMS나 DBMS가 사용하는 엔진에 따라 달라진다. 특히 FK는 DB마다 다른 듯 하다.)
만들어진 인덱스 이름은 PRIMARY이다.
그럼 실제로 실행해보고, 실행시간을 확인해보자.
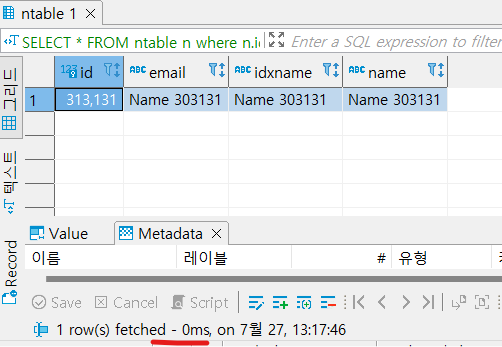
짜잔! 3s -> 0ms로 엄청나게 시간이 단축되었다.
진짜 0ms는 아닐 것이라 생각되지만
표시가 무의미할 정도로 빠른 것이라 추측된다.

자동으로 맹글어주는 인덱스 말고, 직접 인덱스를 만들어 성능을 개선해보자.
// Create Index 인덱스명 On 테이블명(대상 컬럼)
CREATE INDEX idx_nTable_idxname // idxname 컬럼으로 만든 인덱스
ON nTable (idxname);실행계획 확인.
explain
SELECT * FROM ntable n where n.idxname = 'Name 313131';

인덱스를 만들었으므로
Query Optimizer가
" 'idx_nTable_idxname'이라는 인덱스가 있네? 조회할 때 이거 쓸게"
하고 말하고 있다.
실행해보고 성능을 비교해보자. (풀스캔 결과는 이전과 똑같이 3초가 나온다)
SELECT * FROM ntable n where n.idxname = 'Name 313131';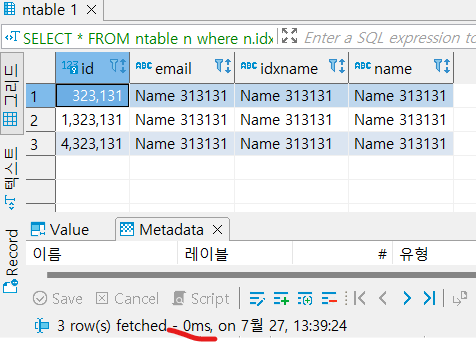
와!0초!
만든 인덱스는 GUI나 CLI 환경에서 따로 확인할 수 있다.
GUI 툴 DBeaver에서는 아래 사진에서와 같이 확인 가능.
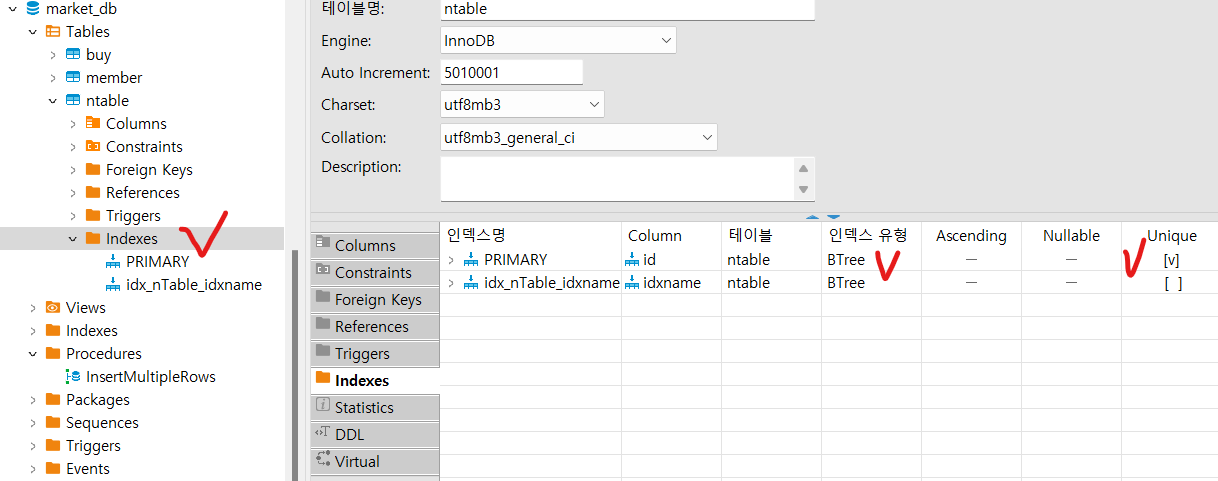
nTable 테이블의 인덱스 목록이다.
저 아래에는 처음에 사용했던 procedure도 보인다.
Btree, Unique 등 자세한 내용은 2부에서 알아보자!
5. 마무으리
2부에서 말하겠지만 인덱스 사용에도 성능감소, 용량 차지 등의 단점이 있을 수는 있는데,
변경이 적으며 조회가 잦은 컬럼에 대해서는 Index를 만들어서 성능을 개선하는 것이 좋다.
예를 들어 어떤 서비스에서 email로 사용자를 데이터베이스에서 찾을 일이 많다고 가정하자.
그렇다면 email 컬럼에 대해서 인덱스를 만들어두는 것이 좋다.
email은 변경될 일이 매우 적은 속성이며, 해당 서비스에서 자주 조회되기 때문이다.
그러므로, 위의 예시 테이블을 개선한다면 'email' 컬럼에 email에 unique constraint를 걸어주고,
자동으로 Unique Index가 생성되게 하면 된다.
ALTER TABLE nTable
ADD CONSTRAINT uk_nTable_email UNIQUE (email);이제 이메일로 데이터를 탐색할 때 인덱스를 사용하게 된다.
'비난 스터디' 카테고리의 다른 글
| [DB]인덱스에 대한 이해- 2부(다중 컬럼 인덱스, 커버링 인덱스, 선행 와일드카드) (0) | 2023.08.07 |
|---|---|
| [Spring]직렬화를 하는 이유 - Serializable과 JSON 직렬화 (0) | 2023.07.20 |
| Java - equals와 hashCode란? 왜 둘을 함께 재정의해야 할까? (0) | 2023.07.05 |
| 중첩 if문 멈춰 - 리팩토링 (2) | 2023.06.29 |



