이번에는 인덱스 사용시의 주의사항과 인덱스 동작방식을 주로 다룹니다.
목차는 아래와 같습니다
==1편(활용)==
1. 인덱스를 사용하는 이유
2. 인덱스의 기본적인 원리 (그림 설명)
3. DBMS에서 실습해보기 - 준비
4. DBMS에서 실습해보기 - 실전
[DB]인덱스에 대한 이해- 1부(기본적인 원리와 실습)
안냥하세요 오늘 주제는 인덱스 관련 내용을 한 번에 쓰려다가 내용이 드릅게 길어져서 둘로 나눕니다. 이 글의 내용은 1. 혼자 공부하는 SQL (책) 2. 코딩애플 (유튜브) 3. 쉬운코드 (유튜브) 의 내
moolzumdao.tistory.com
==2편(원리). 본 게시글==
1. Unique Index, Non-Unique Index 차이
2. 인덱스를 사용하지 못하는 경우 - 다중 컬럼 인덱스(Multiple-Column Index)
3. 커버링 인덱스(Covering Index)
4. 인덱스를 사용하지 못하는 경우 - 선행 와일드카드
1. Unique Index, Non-Unique Index 차이
인덱스는 데이터가 Unique하냐 그렇지 않냐로 나눌 수도 있다.
Unique Constraint에 의해 만들어진 인덱스는 Unique Index이다.
(PK 제약도 해당한다. Primary는 (Not Null + Unique) 이기 때문이다)
MYSQL(Maria)에서는 Unique Constraint와 Unique 인덱스가 한 몸이다.
Unique 제약을 걸면 Unique Index가 생기고, 그 반대도 그렇다.
Unique Index를 삭제하면 Unique 제약 또한 해제된다.
(DBMS마다 다르다. Postgres에서는 별개로 존재할 수 있다고 알고 있다)
그런데, Unique와 Non-Unique는 서로 어떻게 다를까?
Index는 이진탐색의 반갈죽 원리를 토대로 만들어진 기능이라고 했다.
1편의 자료사진을 다시 가져와보자.

위 사진의 배열은 현재 중복값이 없다. Unique 상태이다.
그런데, 만약 중복값이 있는 배열에서 자료를 찾았다면 어떻게 해야 할까?
사진에는 'Found 23, return 5' 라고 되어 있다. 하지만 중복값이 있으면 그렇지 않다.
다음 추가 자료를 보자.

23을 찾았으나 값이 중복될 가능성이 있으므로 탐색을 바로 종료하지 않아야 한다.
다행히도 정렬된 데이터를 대상으로 탐색을 하는 것이므로
그림처럼 '23이 아닌 값' 이 나올 때까지 주변 데이터를 탐색한다.
왼쪽으로 가다가 21을 보고 멈추고, 오른쪽으로 가다가 25를 만나면 멈출 것이다.
결국 3개의 '23' 을 반환한다.
배열에서의 이진 탐색을 예시로 들었지만 DBMS의 인덱스에서도 이는 동일할 것이다.
인덱스는 이진탐색 원리를 기반으로 하고 있기 때문이다.
이는 인덱스를 이해하기 위해 알아두면 좋은 특징이지만,
이러한 미미한 조회성능 향상을 고려하여
억지로 Non-Unique 컬럼을 Unique 컬럼으로 전환하려 노력할 필요는 없다.
위 내용은 많은 학습자료나 온라인 커뮤니티에서 언급되는 내용이지만,
해당 내용을 DBMS 공식문서상에서는 찾지 못했습니다.
그러나,
기본적인 동작원리를 기반으로 한 제 추측과,
여러 스택오버플로우 답변들에서 공통으로 언급되는 부분이기에 그것을 근거로 들어 이 글에 포함했습니다.
Unique vs non-unique index
My table holds nearly 40+ million records., with DML. Would like to know which one of these Unique or non-unique index would be better option for implementation. To give better performance.
stackoverflow.com
가능하면 Unique Index를 써라, 오라클에서는 Unique Index 내에서 값이 발견된다면
추가 작업 없이 즉시 값을 가져올 수 있게 되어있다. (if a unique index is used to probe for a particular value, Oracle can stop processing further index blocks as soon as it finds a match.)
Is there any performance difference between UNIQUE INDEX and INDEX with the same cardinality on MySQL?
I have a table that has id and created_at. Column | Non Unique | Cardinality ------------------------------------- id | 0 | 1000 created_at | 1 | 1000 id is unique, and
dba.stackexchange.com
insert 시 약간의 성능하락, 조회 시 약간의 성능향상이 있다.
2. 인덱스를 사용하지 못하는 경우 - 다중 컬럼 인덱스(Multiple-Column Index)
여태까지는 단일 컬럼을 대상으로 인덱스를 생성했다.
하지만 여러 개의 컬럼을 대상으로 인덱스를 생성할 수도 있다.
여러 개의 컬럼을 대상으로 인덱스를 생성할 때의 주의점을 알아보자.
MySQL :: MySQL 8.0 Reference Manual :: 8.3.6 Multiple-Column Indexes
8.3.6 Multiple-Column Indexes MySQL can create composite indexes (that is, indexes on multiple columns). An index may consist of up to 16 columns. For certain data types, you can index a prefix of the column (see Section 8.3.5, “Column Indexes”). MyS
dev.mysql.com
mysql 문서상에 설명이 잘 되어있다.
그래서 이번엔 문서의 내용을 번역하고 시각자료를 추가해 보았다.
어떤 테이블의 컬럼 col1, col2, col3를 대상으로 다중 컬럼 인덱스를 생성한다고 가정하자.
CREATE INDEX index_name ON table_name (col1, col2, col3);그리고 몇 가지 쿼리를 실행했는데, 어떤 쿼리에서는 인덱스가 사용되었고,
어떤 쿼리에서는 그렇지 않았다. 그 이유를 알아보자.
SELECT * FROM tbl_name WHERE col1=val1; // 인덱스 사용
SELECT * FROM tbl_name WHERE col1=val1 AND col2=val2; // 인덱스 사용
SELECT * FROM tbl_name WHERE col2=val2; // 인덱스 사용불가
SELECT * FROM tbl_name WHERE col2=val2 AND col3=val3; // 인덱스 사용불가왜 (col1, col2, col3) 컬럼을 대상으로 생성한 인덱스는 어떤 경우에는 사용되지 못할까?
일단 만들어진 인덱스를 보자.
col1, col2, col3은 모두 숫자 타입이며, 중복이 가능한 column이다.
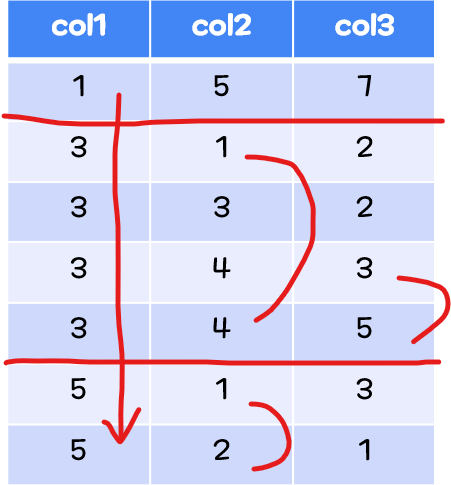
다중 컬럼 인덱스는 위 자료처럼
- col1을 우선 정렬하고
- col2은 그룹화된 col1에 맞춰 정렬된다
- 즉, 같은 col1인 '3' 에 대해서 정렬(1, 3, 4, 4) 된다.
- 같은 col1인 '5'에 대해서 정렬(1, 2) 된다.
3. col3은 그룹화된 col1, col2에 맞춰 정렬된다.
col1의 값이 같은 행에 대해서는 col2의 값을 기준으로 데이터를 정렬하고,
'col1'과 'col2'의 값이 같은 행의 경우 'col3'의 값을 기준으로 데이터가 정렬되는 것이다.
다시 말하면,
col2는 그 자체로는 정렬되어 있지 않다.
(5134412)
하지만 같은 col1 그룹에 대해서는 정렬되어 있다.
(
1-5,
3-1344,
5-12
)
이제 왜 아래의 SQL이 인덱스를 사용하지 못했는지 알아보자.
1. SELECT * FROM tbl_name WHERE col2=val2; // 인덱스 사용불가
2. SELECT * FROM tbl_name WHERE col2=val2 AND col3=val3; // 인덱스 사용불가
1. where col2
좀 전에 말했듯이, 위의 인덱스에서는 col2는 그 자체로는 정렬되어있지 않다(5134412).
정렬되어있지 않기 때문에 사용할 수 없는 인덱스이며, 풀스캔을 하게 된다.
2. where col2 AND col3
좌변인 col2는 풀스캔 처리된다. (위에서 언급했듯이)
우변인 col3 또한 풀스캔 처리된다.
- 'col1 AND col2 AND col3'이라면 'col3'을 조회하는 시점에 인덱스를 사용할 수 있으나, col1로 시작하지 않아 불가능
왜 아래의 SQL이 인덱스를 사용할 수 있었는지 알아보자.
1. SELECT * FROM tbl_name WHERE col1=val1; // 인덱스 사용
2. SELECT * FROM tbl_name WHERE col1=val1 AND col2=val2; // 인덱스 사용1. where col1
인덱스는 col1, col2, col3 순으로 정렬되어있다.
가장 첫 순위인 col1은 그 자체로도 이미 정렬이 되어있으므로(자료사진상 133355)
인덱스를 사용하여 조회하게 된다.
2. where col1=val1 AND col2=val2
- 우선 'col1' 을 인덱스를 사용해서 조회한다. val1은 3이라고 가정한다.
- '3'의 값을 가진 col1이 4개가 나온다.
- 그룹화된 col1 (즉 3)에 대해서 col2는 정렬되어 있다 (1344)
- 1, 3, 4, 4 데이터 중 val2에 해당하는 값을 이진탐색으로 찾는데, 이 때도 인덱스가 사용된다.
=> 결국 col1과 col2 모두 인덱스를 사용해서 조회된다.
정리하며
다중 컬럼 인덱스는 대상 컬럼들의 선언 순서가 중요하다.
대상 컬럼을 (col1, col2, col3) 로 지정했기 때문에
'where col2 AND col3' 조회는 인덱스를 사용하지 못했다.
(col2, col3, col1)로 지정했다면?
'where col2 AND col3' 조회는 인덱스를 사용할 수 있을 것이다.
SELECT col1, col2
FROM Table
WHERE col1 = val1 AND col2 = val2
3. 커버링 인덱스(Covering Index)
원하는 정보가 모두 인덱스에 존재할 때,
인덱스를 사용해서 데이터를 찾은 후 원본 데이터를 참조하는 과정을 거치지 않고
인덱스상의 정보를 즉시 반환할 수 있게 하는 인덱스를
커버링 인덱스라고 한다.
아래와 같이 'email, name' 을 대상으로 인덱스를 생성한다.
CREATE INDEX idx_email_name ON table_name (email, name);그리고 아래와 같은 쿼리를 실행한다.
SELECT email, name
FROM table_name
WHERE email = val@mail.com;위의 쿼리는 idx_email_name 인덱스를 사용해서 조회된다.
해당 인덱스에서 가장 왼쪽에 선언한 기준 컬럼이 'email' 이기 때문에, email 조회 시에 해당 인덱스가 사용될 수 있다.
일반적으로는 인덱스에서 정렬된 컬럼을 통해 데이터를 찾고,
원본 테이블 행으로 이동하여 SELECT절에서 요구하는 항목들을 반환한다.
하지만 인덱스에서 자체적으로 email과 name을 가지고 있기 때문에
불필요한 이동 작업을 거치지 않아도 된다.

위의 인덱스는
email을 기준으로 원본 테이블의 데이터를 찾는 일반적인 시나리오에서도 사용될 수 있고,
이 인덱스를 사용하는 sql문의 Select절이 'email' or 'name' or 'email, name' 일 경우에는
커버링 인덱스로 사용되는 것이다.
멀티컬럼 인덱스를 커버링 인덱스로 사용하려고 할 때,
직전 챕터에서 언급했던 것처럼 대상 컬럼의 선언 순서가 중요함을 기억하자.
4. 인덱스를 사용하지 못하는 경우 - 선행 와일드카드
다시 말하지만, 찾으려는 데이터가 '인덱스 속에 정렬되어 있다면' 인덱스를 사용한 탐색이 가능하다.
이 사실을 다시 한번 상기하며, 와일드카드 위치에 따라 인덱스가 사용되지 못하는 이유를 알아보자.
결론부터 말하자면 인덱스는
후행 와일드카드만이 존재하는 경우에만 사용 가능하다.
A로 시작하거나,
A로 끝나거나,
A가 포함된 경우를 검색하기 위해 '%' 와일드카드를 사용한다고 가정하자.
결과는 다음과 같다.
LIKE 'A%' - 인덱스 사용 가능
LIKE '%A' - 인덱스 사용 불가능
LIKE '%A%' - 인덱스 사용 불가능
왜 그런지 이해하는 방법은 어렵지 않다.
1편의 자료사진을 다시 보자.
1. 특정 문자로 시작하는 이름 찾기 - 'A%'
인덱스에서 'A' 로 시작하는 이름인 'Alice'를 쉽게 찾을 수 있다.
인덱스는 알파벳 오름차순으로 정렬되어있기 때문이다.
2. 특정 문자로 끝나는 이름 찾기 - '%d'
인덱스에서 'd'로 끝나는 이름인 'David'를 찾을 수 있을까?
그렇지 않다.
인덱스는 문자열의 맨 앞부터 정렬하기 때문에, 선행 와일드카드(Leading Wildcard)의 사용은
인덱스를 사용할 수 없게 한다.
위 사진만으로는 'David'를 즉시 탐색 가능한 것처럼 오해할 수 있어, 추가 자료를 첨부한다.
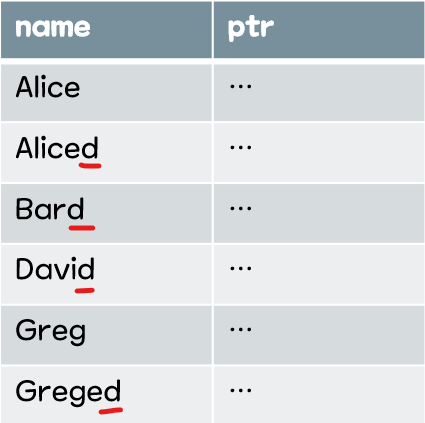
사진에서 알 수 있듯이, 'd' 로 끝나는 데이터는 정렬되어있지 않다. 결국 풀스캔을 하게 된다.
3. 특정 문자가 포함된 이름 찾기 - '%d%'
2번과 같은 이유로 인덱스를 사용하지 못한다.
직접 테스트해보기
DBMS에서 직접 실행해본 실행계획 결과는 다음과 같다.
테이블명: ntable
인덱스 대상 컬럼: 3개의 컬럼 중 'ukname' 에만 적용 (Unique Constraint)
데이터: 약 200만건
explain // 실행계획 보기
SELECT * FROM ntable n where n.ukname like 'name 133%'; // 후행 와일드카드. 인덱스가 사용됨
explain // 실행계획 보기
SELECT * FROM ntable n where n.ukname like '%name 133'; // 선행 와일드카드는 인덱스 사용 불가
여기까지 인덱스 동작 방식과 주의사항에 대해서
정리해보았습니다.
감자합니다.
Btree 같은 것도 다루려고 했는데
제가 설명할 수 있을 정도로 이해를 하기가 어렵더라구요
나중에 강해지면 돌아오겠습니다.
바
'비난 스터디' 카테고리의 다른 글
| [DB]인덱스에 대한 이해- 1부(기본적인 원리와 실습) (0) | 2023.07.27 |
|---|---|
| [Spring]직렬화를 하는 이유 - Serializable과 JSON 직렬화 (0) | 2023.07.20 |
| Java - equals와 hashCode란? 왜 둘을 함께 재정의해야 할까? (0) | 2023.07.05 |
| 중첩 if문 멈춰 - 리팩토링 (2) | 2023.06.29 |



